Multi-tenant schema design allows SaaS apps to serve multiple customers (tenants) on shared infrastructure while keeping their data isolated. Choosing the right database model impacts cost, security, and scalability. Here’s a quick breakdown of the three main models:
- Shared Database, Shared Schema: All tenants share the same tables, separated by a
tenant_id. It's cost-efficient but risks "noisy neighbor" issues and requires strict filtering to avoid data leakage. - Shared Database, Separate Schemas: Tenants share a database but get individual schemas for better isolation. This balances cost and separation but complicates migrations and maintenance.
- Separate Databases per Tenant: Each tenant gets their own database. This provides the highest isolation and suits compliance-heavy industries but is expensive and operationally complex.
Key takeaway: Start with a shared schema for cost efficiency, or explore free low code platforms to test these architectures, but plan for scalability and compliance needs. Use tools like Row-Level Security (RLS) for data isolation, and automate schema migrations to reduce errors. Your choice should align with your app's size, tenant count, and regulatory requirements.
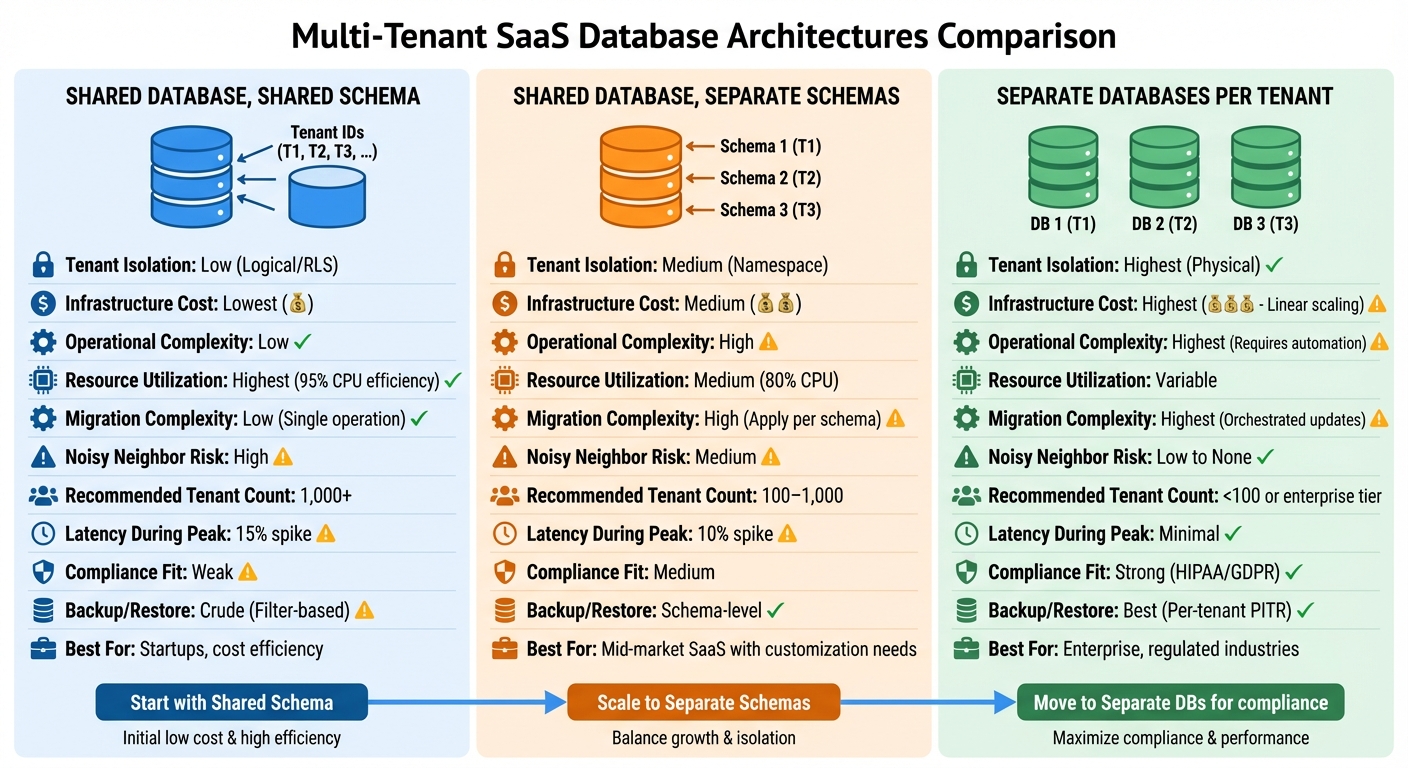
Multi-Tenant Database Architecture Comparison: Shared Schema vs Separate Schemas vs Separate Databases
SQL Multi-Tenant Databases: Architecture, Design Patterns & Best Practices
sbb-itb-33eb356
Shared Database, Shared Schema Model
In the shared database, shared schema model, all tenants share the same database instance and tables, with data separated by a tenant_id column in each table. This setup ensures logical isolation between tenants, much like a filing system where every document is labeled with a unique identifier for easy organization.
This model is considered the most cost-efficient option for SaaS applications. By using a single database instance, it significantly reduces infrastructure and licensing expenses. For instance, 2026 benchmarks revealed that this approach achieved 95% CPU utilization efficiency and 85% memory efficiency across 1,000 tenants. Sanjeev Sharma, a Full Stack Engineer at E-mopro, highlights its simplicity:
"Start with RLS for simplicity if team understands the complexity."
Let’s explore the operational advantages and challenges that come with this model.
Benefits and Trade-Offs
This model simplifies operations in ways that isolated frameworks cannot. Centralized maintenance ensures updates and changes are applied to all tenants at once, eliminating the need for complex coordination across multiple databases. Adding new tenants is also straightforward - often as simple as inserting a new row in a central tenants table.
However, the simplicity comes with trade-offs. If a WHERE tenant_id = ? filter is accidentally omitted, it could lead to security vulnerabilities or performance issues. Additionally, shared schema environments are susceptible to the "noisy neighbor" effect, where resource contention during peak loads can cause latency spikes of up to 15%.
Industry Implementation Example
Modern platforms use PostgreSQL's Row-Level Security (RLS) to tackle isolation challenges. Instead of relying entirely on application-level filtering, RLS enforces data separation directly at the database level. As Hunchbite explains:
"RLS operates at the database level. The application doesn't explicitly add WHERE tenant_id = ? to every query - Postgres adds it automatically based on the policy."
To ensure secure data isolation, developers set a session variable, such as SET LOCAL app.current_tenant_id, at the start of each transaction. Object-Relational Mappers (ORMs) like EF Core or Sequelize can also implement global query filters, automatically appending tenant-specific filters to all queries. RLS policies have been shown to reduce data leakage risks by up to 95%.
Performance optimization in this model requires an effective indexing strategy. For example, indexes should always include tenant_id as the leading column to improve query performance. As ER Flow notes:
"The tenant_id always comes first in compound indexes for multi-tenant tables - it is the highest-selectivity filter that eliminates the most rows in the earliest possible scan step."
Comparison Table
| Feature | Shared Schema Model |
|---|---|
| Tenant Isolation | Logical (Policy-based) |
| Infrastructure Cost | Lowest |
| Operational Complexity | Low |
| Resource Utilization | Highest (95% CPU efficiency) |
| Migration Complexity | Low (Single operation) |
| Scalability | High (Vertical or Horizontal via Sharding) |
| Noisy Neighbor Risk | High (Potential for contention) |
Shared Database, Separate Schemas Model
In this model, a single database is shared, but each tenant gets its own distinct namespace, or schema. For example, in PostgreSQL, every tenant is assigned a unique schema that serves as a private container for their tables, indexes, and data. The application ensures isolation by setting the search_path at the start of each database connection.
This approach strikes a balance between cost savings and better isolation. It’s ideal for SaaS platforms with 100 to 1,000 tenants, especially when customization is needed without the high costs of dedicated databases. Unlike shared schemas, this model allows for tenant-specific tweaks, like creating custom indexes or modifying table structures for feature rollouts.
From a security standpoint, this model offers an extra layer of protection. For a data breach to occur, the application would need to fail in setting the correct search_path and explicitly reference another tenant’s schema. Additionally, you can isolate tasks like exporting or restoring a single tenant’s schema without affecting others.
Schema-Level Isolation Benefits
Organizing tenant data into separate namespaces helps minimize noisy neighbor issues. Since each tenant’s data is confined to its own schema, indexes remain smaller and more focused, often leading to better query performance for tenant-specific workloads. For example, benchmarks show that separate schemas experience about a 10% latency increase during peak times, compared to 15% for shared schemas. They also achieve an 85% isolation efficiency rating versus 70% for shared schema environments. This makes them a good fit for mid-market customers who need better data separation but don’t require full regulatory compliance. The namespace design also naturally prevents accidental cross-tenant joins. However, this improved isolation comes with operational challenges.
Challenges in Low-Code Platforms
Managing separate schemas can complicate operations, which is especially relevant for low-code platforms. Software Engineer Asad Ali points out:
"Tooling such as EF migrations and DevOps practices must be precisely managed."
One major hurdle is handling migrations. Adding a new table or column means applying the change to each tenant’s schema individually, which can be a slow process. For instance, a SaaS platform with 500 tenants reported that migrations took 20% longer under this model. As AppMaster Editorial explains:
"Migrations often surprise teams. When you add a new table or column, you must apply the change to every tenant schema. With 1,000 tenants, you need a process."
For developers working with U.S.-based low-code platforms, these challenges directly affect deployment strategies and costs. A routing layer must be set up to adjust the database search_path before running business logic. Tools like EF migrations or Knex must be configured to loop through all tenant schemas, and connection pooling becomes trickier due to the dynamic nature of schema switching. Studies estimate that managing separate schemas requires about 30% more effort compared to shared schema models because of the increased number of schemas. Additionally, PostgreSQL can struggle with performance when handling thousands of namespaces, making it crucial to monitor system catalogs and connection pooling. Transitioning a SaaS platform from a shared schema (with row-level security) to separate schemas typically takes 5 to 7 weeks of engineering work. These operational complexities often lead teams to explore models aimed at compliance.
Comparison Table
| Feature | Shared Schema | Separate Schemas |
|---|---|---|
| Tenant Isolation | Low (Logical/RLS) | Medium (Namespace) |
| Infrastructure Cost | Lowest | Medium |
| Operational Complexity | Low | High |
| Resource Utilization | High (95% CPU) | Medium (80% CPU) |
| Migration Complexity | Low (Apply once) | High (Apply per schema) |
| Noisy Neighbor Risk | High | Medium |
| Recommended Tenant Count | 1,000+ | 100–1,000 |
| Latency During Peak Loads | 15% spike | 10% spike |
Separate Databases per Tenant Model
The dedicated database model offers the highest level of isolation, especially for industries with strict compliance needs. In this setup, each tenant has their own database, providing physical separation. For instance, a healthcare SaaS platform could create a new PostgreSQL database for every hospital system that joins, ensuring patient data stays completely separate from other organizations.
This model is particularly appealing for businesses operating in regulated industries. For companies adhering to standards like HIPAA, SOC 2 Type II, or FedRAMP, this approach often becomes the most practical solution for meeting compliance requirements. It also simplifies data residency obligations. If a customer needs their data stored in a specific region to comply with GDPR, their dedicated database can be deployed in that region.
Another advantage is workload isolation. Heavy queries from one tenant won't impact others. Plus, you can tailor database configurations, backups, and even versions to meet individual tenant needs. For example, Azure SQL Database supports up to 5,000 databases per logical server, making this model scalable for larger SaaS applications.
Compliance and Isolation Benefits
For industries with strict regulatory and data residency rules, moving from logical to physical isolation is often essential. This model significantly reduces the risk of cross-tenant data breaches. The AppMaster Editorial Team highlights this point:
"Separate databases are the simplest to reason about. Accidental cross-tenant reads are much less likely, and a permission mistake tends to affect only one tenant".
This simplicity is crucial when presenting compliance evidence to auditors or customers.
The model also enables precise maintenance. For example, if a tenant mistakenly deletes important records, you can restore just their database without impacting others.
Additionally, this architecture supports tiered service models. Many SaaS providers use a hybrid approach where free or trial users share a database, while enterprise customers get dedicated instances. This allows companies to balance infrastructure costs with revenue. These benefits stand out compared to the shared schema models discussed earlier.
Cost and Scalability Considerations
Despite its advantages, this model comes with higher costs. Alex Thompson, CEO of ZeonEdge, explains:
"Operational complexity scales linearly with the number of tenants (1,000 tenants = 1,000 databases to manage, back up, patch, and monitor)".
Every dedicated database adds resource, licensing, and maintenance expenses. Connection pooling also becomes more challenging since each database needs its own pool. Schema migrations require automation to ensure updates are applied across all tenant databases. Proprietary low-code platforms can help streamline these processes by automating database creation and provisioning workflows during tenant onboarding.
To control costs, consider elastic pools on platforms like Azure SQL. Elastic pools let multiple databases share compute resources, avoiding the need to allocate peak capacity for each tenant. Additionally, using a catalog database - a central directory mapping tenant IDs to connection strings - enables dynamic query routing, simplifying database management.
Comparison Table
| Feature | Shared Schema | Separate Schemas | Separate Databases |
|---|---|---|---|
| Tenant Isolation | Low (Logical/RLS) | Medium (Namespace) | Highest (Physical) |
| Infrastructure Cost | Lowest | Medium | Highest (Linear scaling) |
| Operational Complexity | Low | High | Highest (Requires automation) |
| Migration Complexity | Low (Apply once) | High (Apply per schema) | Highest (Orchestrated updates) |
| Noisy Neighbor Risk | High | Medium | Low to None |
| Recommended Tenant Count | 1,000+ | 100–1,000 | <100 or enterprise tier |
| Compliance Fit | Weak | Medium | Strong (HIPAA/GDPR) |
| Backup/Restore | Crude (Filter-based) | Schema-level | Best (Per-tenant PITR) |
Multi-Tenant Schema Design Practices for Low-Code Apps
Tenant-Aware Context Propagation
Every request in a multi-tenant system should carry its tenant ID from the outset. Middleware can handle this by extracting the tenant ID - whether it’s from a subdomain, a JWT claim, or a custom header like X-Tenant-ID - and storing it in a request-scoped context. This ensures tenant-specific operations are consistently applied throughout the request lifecycle.
Owen Jones, Founder & Technical Director at OLXR LIMITED, underscores the importance of this practice:
"A single missing WHERE TenantId = @TenantId in a raw SQL query is a data breach. Build tenant isolation into your infrastructure, not just your conventions."
For platforms like AppMaster, integrating the tenant_id from the authenticated user's context at the start of every business process ensures that all subsequent data operations are correctly scoped. This step is critical in avoiding security lapses, such as forgetting to filter queries by tenant. To further safeguard data, Row-Level Security (RLS) policies can be implemented. These policies automatically append tenant filters to every query, adding an extra layer of protection against application-level mistakes.
Optimizing database performance is also key. Composite indexing, where each index begins with tenant_id (e.g., tenant_id, created_at), allows the database to efficiently locate tenant-specific data. Additionally, caching tenant metadata and connection strings in Redis can help reduce the load on the central catalog database. Proper tenant-aware context management also simplifies schema migration processes, which are vital for maintaining data integrity across tenants.
Schema Migration Strategies
Managing schema migrations in a multi-tenant architecture is more complex than in single-tenant systems. Each migration must be applied individually for every tenant, which increases both operational demands and potential risks. As the AppMaster Editorial Team explains:
"A schema change is no longer 'run once,' it's 'run for every tenant.' That adds operational work and risk, so teams often version schemas and run migrations as controlled jobs."
For systems using separate schemas or databases, batching migrations can help balance resource usage and allow for validation between stages. Tracking schema versions for each tenant in a central catalog ensures a systematic rollout and minimizes errors.
Asha Kumar, Principal Engineer at Mongoose.Cloud, advocates for a careful, phased approach:
"Migrations are the riskiest part of tenancy work. Our 2026 playbook focuses on safe, observable steps."
This approach involves shadow writes (duplicating data to both the old and new schemas), canary reads for a subset of tenants, and a closely monitored rollout. Designing migrations as idempotent jobs with automatic rollback mechanisms helps mitigate failures without manual intervention. Additionally, using foreign key constraints with ON DELETE CASCADE ensures thorough data cleanup when tenant data is removed. These strategies reduce the risks associated with migrations and ensure data consistency across tenants.
Low Code Platforms Directory as a Resource
Choosing the right low-code platform is critical for building multi-tenant SaaS applications. The Low Code Platforms Directory is a valuable tool for this process. It offers advanced filters to help you identify platforms with essential multi-tenant features like Row-Level Security, custom schema migrations, and elastic connection pooling. These capabilities are indispensable for scaling SaaS applications effectively.
The directory also highlights platforms tailored to specific needs, such as compliance with regulations like HIPAA or GDPR, or the ability to manage thousands of tenants within a shared-schema model. By streamlining the evaluation process, this resource helps developers find tools that align with their architectural requirements, supporting best practices in tenant isolation and schema management outlined in this article.
Conclusion
Main Points Recap
Choosing the right database model boils down to your specific needs. Each option comes with its own pros and cons that impact cost, security, and operational complexity. These trade-offs tie back to the architectural practices discussed earlier.
- Shared schemas: Offer low overhead but require rigorous filtering to maintain data separation.
- Separate schemas: Provide a balance between isolation and customization, making them ideal for mid-market requirements.
- Dedicated databases: Deliver the highest level of security and isolation but come with significantly higher resource demands.
Performance benchmarks reveal shared schemas often experience high CPU usage with occasional latency spikes. On the other hand, database-per-tenant setups demand far more resources. For startups, shared schemas are a good starting point, while enterprises often lean toward dedicated databases to meet compliance standards.
As Owen Jones of OLXR wisely said:
"The schema pattern you choose on day one will still be running your business on day one thousand. It's worth an extra week of thought before you write the first migration."
The key takeaway? Choose a model that aligns with your platform's current needs while leaving room for future growth and compliance.
Next Steps
Now that you understand the trade-offs, it's time to align your platform's needs with the right tools. Selecting a low-code platform equipped for multi-tenant architecture can simplify implementation. The Low Code Platforms Directory is a great resource. It helps you filter platforms based on features like Row-Level Security, automated schema migrations, and elastic connection pooling.
Leverage this directory to streamline your search and ensure your platform supports the architectural best practices outlined in this article. This way, you can set a strong foundation for your multi-tenant system while staying adaptable to future requirements.
FAQs
When should I move from shared schema to separate schemas or databases?
Transitioning from a shared schema to individual schemas or databases in a multi-tenant SaaS setup hinges on factors like data isolation, regulatory requirements, and scalability. Using a shared schema is a smart starting point - it keeps things straightforward and budget-friendly. However, as your tenant base expands or demands for stricter security, performance isolation, or compliance arise, moving to separate schemas or databases may become necessary. This decision should align with your overall SaaS architecture strategy, ensuring you strike the right balance between cost and complexity.
How do I prevent cross-tenant data leaks in a shared schema setup?
To keep data secure in a shared schema, make sure every query includes a tenant_id condition to enforce strict filtering. Middleware can help by automatically adding the tenant context to queries, reducing the risk of missing filters. Also, don't forget to index the tenant_id column - this boosts performance and makes it easier to spot any unusual activity. By following these steps, you can maintain strong data isolation and prevent accidental leaks in multi-tenant setups.
What’s the safest way to run migrations across many tenants?
The best way to handle database migrations is through staged rollouts combined with automation. Start by using version control for your migration scripts - this keeps every change traceable and well-documented. Make sure your migrations are idempotent, meaning they can be safely run multiple times without causing issues. Wrapping changes in transactions is another must - it helps prevent data corruption if something goes wrong.
To minimize risks, deploy migrations incrementally, like with a canary deployment. This allows you to monitor for potential errors on a smaller scale before rolling out to everyone. Automating these steps within your CI/CD pipelines, along with using validation tools, adds an extra layer of reliability and helps catch problems early.


